
74 Amfitheas Avenue, 17564, Paleo Faliro, Athens / Greece
| T: +30.2109230420 | E: info@noetik.gr
TECHNICAL ARTICLES
RAG | AI | Compliance

Introduction
As organizations move beyond generic AI use cases, a clear requirement is emerging:
AI systems must operate on internal knowledge—securely, accurately, and cost-effectively.
Whether it’s internal documentation, customer support data, or operational know-how, companies increasingly need AI that can answer questions based on their own data, without exposing that data unnecessarily.
This is where private AI knowledge systems (commonly implemented using Retrieval-Augmented Generation — RAG) become critical—not just as a concept, but as a production-grade architectural pattern.
A private AI knowledge system works by:
Unlike traditional AI usage, the model does not rely purely on pretraining. Instead, it is anchored to your organization’s data at runtime.
At a high level, the system consists of:
When a user asks a question:
Real-World Example
Below is a real implementation by Noetik, showcasing a production-grade private AI knowledge system. The platform ingests and processes multiple data sources—including URLs, plain text, PDFs, Word documents, images, audio, and video—transforming them into structured knowledge through intelligent chunking and embedding pipelines.
Content is indexed using both semantic vector search and keyword-based (Lucene) indexing, enabling hybrid retrieval strategies that balance precision and recall. This allows users to query their data using semantic understanding, exact matching, or a combination of both.
On the inference layer, the system provides flexible reasoning options. Organizations can choose to run models locally (e.g. via Ollama) for maximum data control, or leverage enterprise-grade APIs such as Anthropic, OpenAI, or Azure OpenAI. Additionally, users can control how responses are generated by selecting between strict RAG (fully grounded answers), general knowledge mode, or hybrid approaches that combine internal data with model knowledge.
At a practical level, every source is parsed, broken down into manageable chunks, transformed into embeddings, and indexed for fast and accurate retrieval. Each item remains traceable and available for querying in real time.
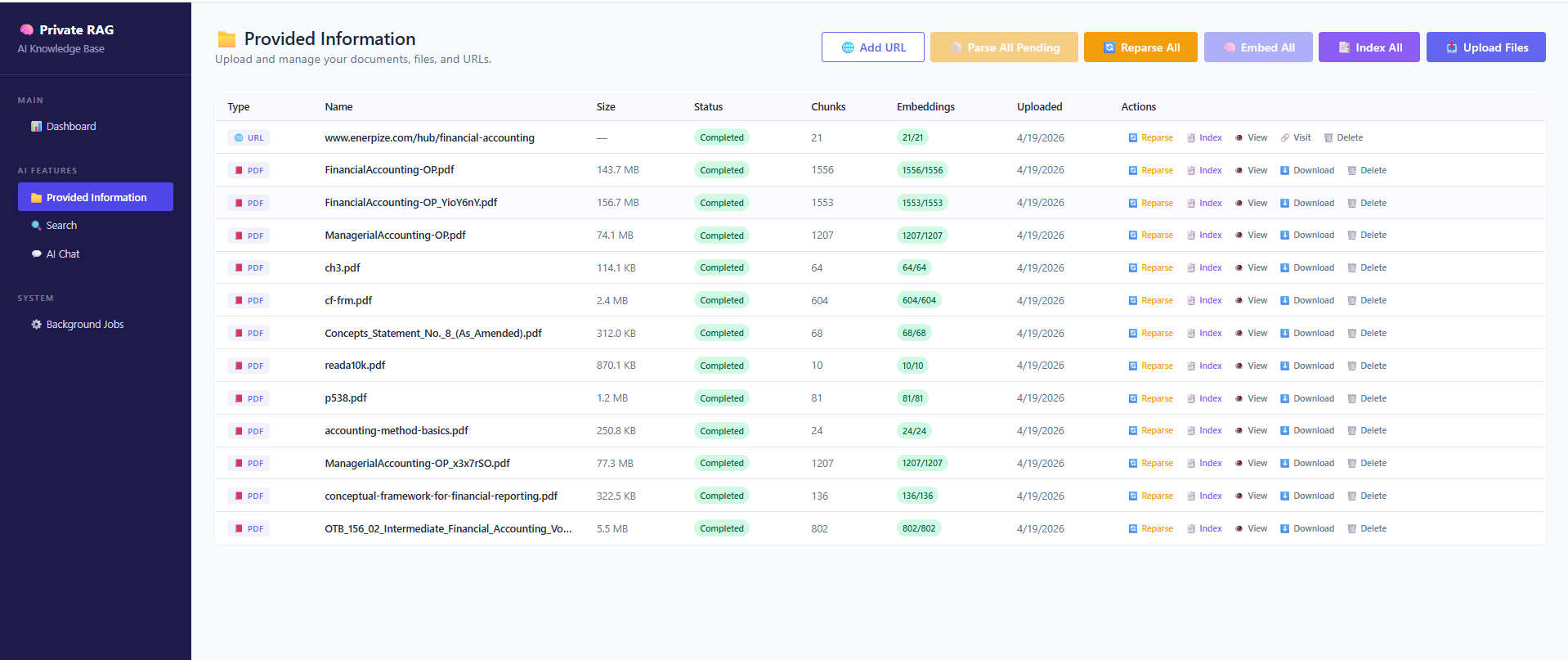
A RAG system's knowledge base
Retrieval Layer: Not Just “Search”
Modern systems support multiple retrieval strategies:
Hybrid approaches are typically preferred in production, as they balance precision and recall—especially in technical or structured domains.
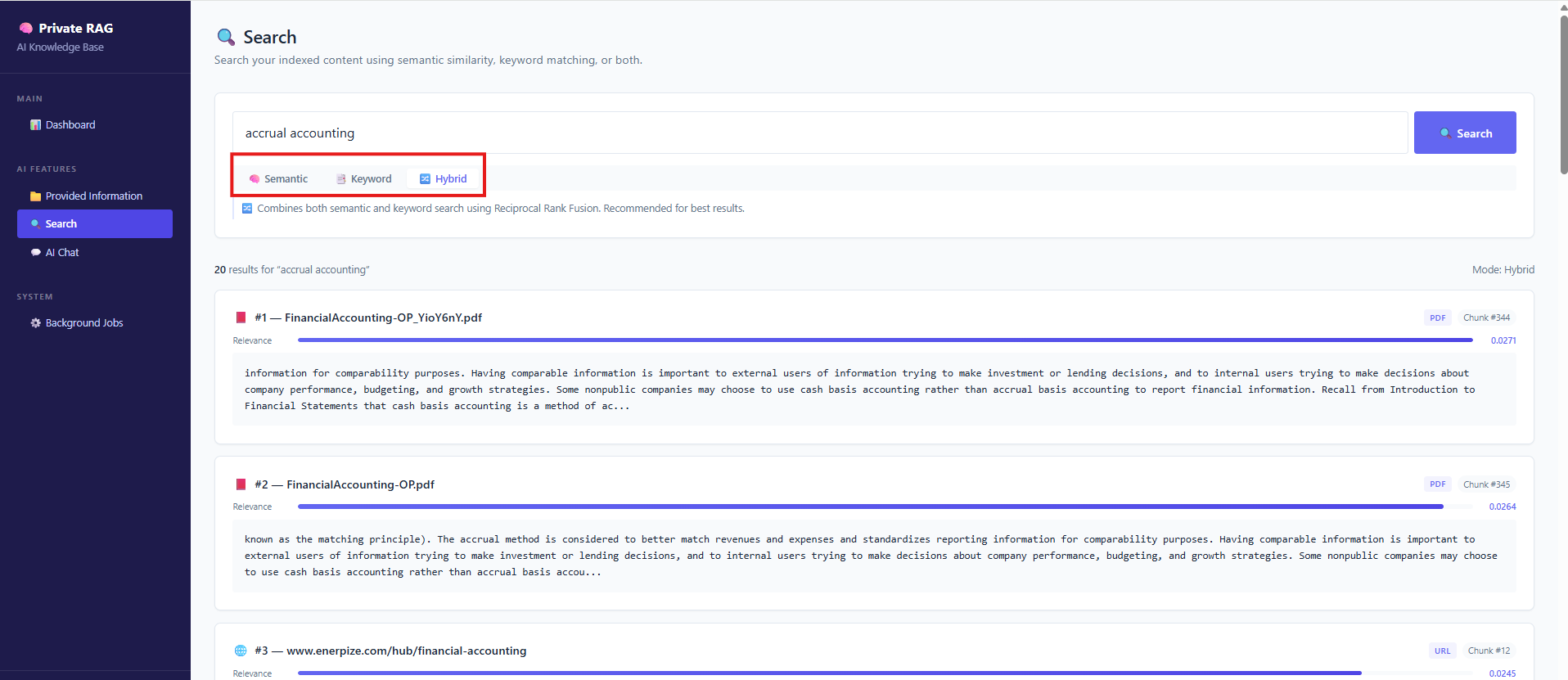
Retrieval Layer - Semantic, Index or Hybrid search
From Retrieval to Answer Generation
Once relevant information is retrieved, it is passed to the AI model, which generates the final response.
Notice that:
This is what differentiates a production RAG system from a generic chatbot.
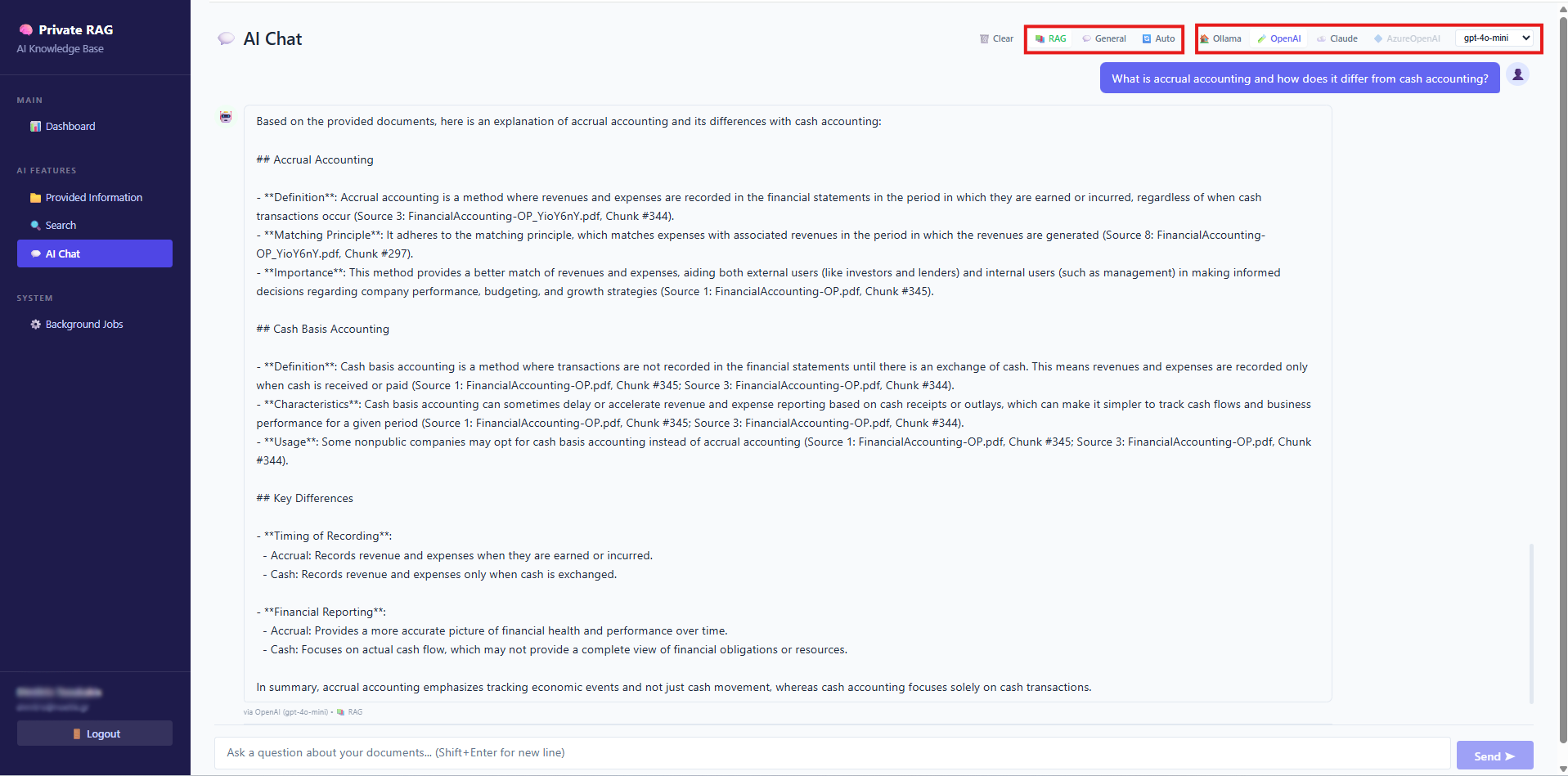
Answer Generation based on our Knoweldge Base
Privacy in AI Knowledge Systems
When deploying AI systems on internal data, privacy is not a feature—it is a design constraint.
In a typical architecture, your data interacts with:
The key question becomes:
Where is your data processed, and how much of it is exposed per request?
Before documents are indexed, they are split into smaller segments (chunks).
This has direct privacy implications:
Proper chunking reduces:
Your data is not stored as raw text during retrieval—it is converted into embeddings and stored in a vector database.
Privacy considerations include:
Even though embeddings are not human-readable, they still represent your data and must be treated as sensitive.
The final step is where retrieved data is sent to an AI model.
This is where most privacy concerns arise.
You have three main options:
This is typically the best balance between performance and control.
Trade-offs:
Suitable for:
In practice, many enterprise systems combine approaches:
This allows organizations to balance:
Delivering Enterprise AI Systems with Confidence
At Noetik, we design and implement enterprise-grade AI solutions tailored to each organization’s needs. With a strong background in custom software and system integration, we build AI systems that are scalable, secure, and aligned with real business requirements.
Our approach combines intelligent automation, data integration, and advanced AI architectures to support use cases such as private knowledge systems, decision support tools, and process automation.
Whether your requirement is a privacy-first RAG system, a hybrid AI architecture, or a broader AI initiative, Noetik can design, implement, and operate a solution adapted to your infrastructure, compliance requirements, and cost constraints.
We work as a long-term technology partner, ensuring that every AI system is reliable, maintainable, and aligned with your business strategy.
 CALL US
CALL US CONTACT
CONTACT
Share this page